Linux and L2 Cache; Sempron vs. Athlon
by Kristopher Kubicki on August 18, 2004 2:29 AM EST- Posted in
- Linux
Mental Ray
Mental Ray 3.3.1 is still a 32-bit program, so even though we have tested it on 64-bit platforms in the past, it has and will continue to exist as a 32-bit program for our analysis.
We ran Mental Ray from the command line with the same benchmark file we have been using in the past.
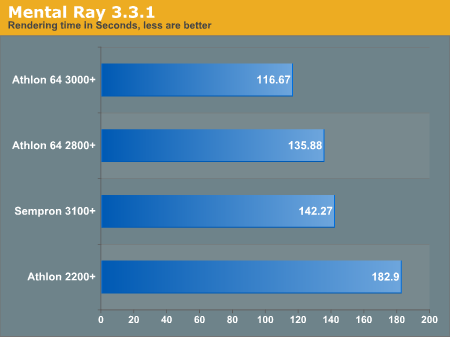
Mental Ray appears to be less L2 cache intensive than many of our other benchmarks. Although there is a scalable difference between the Athlon 64 2800+ and the Sempron 3100+, we see much faster times when we increase the clock and the cache, as seen on the Athlon 64 3000+.
POV-Ray
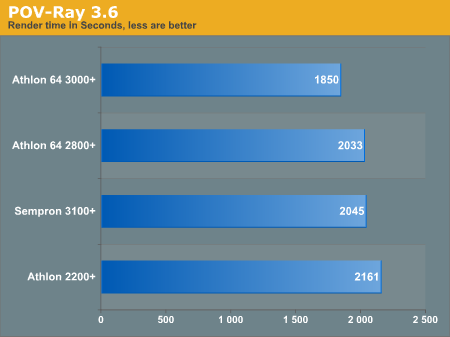
We have had some discrepancies with POV-Ray 3.50c in the past, so from now on we are sticking to self compiled 3.6 binaries while running the official benchmark.ini. The program was compiled using the standard ./configure and make, with no induced optimizations.








59 Comments
View All Comments
Gatak - Thursday, August 19, 2004 - link
I would like to see a Gentoo 64bit Linux comparison. I know this would take a little longer to achieve, but It would probably show better what 64bit performance would be as everything, including GCC and GLibC would be compiled for the platform.Matthew Daws - Thursday, August 19, 2004 - link
As a followup to this, I've now realised that TSCP is a chess program! Thus it is most unlikely that GCC is getting any performace gain out of SSE(2) (although, again, it might be using a few SSE commands). That is, unless the source-code for TSCP explicitly uses SSE2, either via intrinsics, or via inline assembly.Having looked at the source-code, this is not the case. GCC is in no way making large use of SSE or SSE2. So I fully agree with you Tau
Curious: On my Celeron 2GHz laptop, I get a score of 258 K Nodes/sec with the default executable I downloaded (TSCP 1.81). Compiling with GCC "march=pentium4 -O3" I get 269K and with "march=pentium4 -O2" I get 260K. Methinks something is wrong, as this is what Kris gets with an Athlon64 2800+
Kris: Maybe you need to look at what is going on here...
Matthew Daws - Thursday, August 19, 2004 - link
#6: GCC can indeed produce SSE(2) output. There are two modes for SSE: scalar and packed. In scalar, what you get is basically x87 with a flat register file: this makes compiler writing easier, and generally improves performance a bit (a lot for P4 systems, as they don't have the FXCHG intstruction for free anymore). In packed mode, SSE runs in proper SIMD mode, with possibly huge performance increases.Now, GCC can issue scalar SSE instructions: indeed, this seems to be the default for the 64-bit compiler, and on my 32-bit system, I notice GCC sneaking in some SSE instructions to do with integer to floating-point convert, say. Under certain -march options, GCC will do most floating-point math in scalar SSE (I am currently trying to help debug some issues with this under Windows, in fact).
GCC cannot automatically issue packed code though, which I guess is what was bothering you: indeed, it takes a very, very clever compiler to automatically start doing SIMD stuff.
However, this does mean that I am a little surprised that the AthlonXP was dropped for this test:
i) AthlonXP DOES HAVE SSE, just not SSE2. As SSE2 only introduces support for "double" floating-point types (at least as far as GCC can exploit), does TSCP use double types?
ii) As I mentioned about, moving from x87 to scalar SSE(2) only makes a noticable difference on P4 systems: P3 and Athlons have much better x87 (hacks one could say) so I wouldn't expect a huge difference.
In summary, I wouldn't expect to see SSE2 make a huge difference here, but it is probably being used.
--Matt
theoldwizard - Thursday, August 19, 2004 - link
I come from the "commercial" world where 64 bit processors (Alpha EV4, 5, 6 and 7 and UltrSparc III) are realy 64 bits. By this I mean all internal data paths, registers, etc, etc are really 64 bits.If an Athalon 64 is really a 32 bit core with extra opcodes and microcode to make it look like a 64 bit processor I am very disappointed.
Everyone has been saying the big advantage of 64 bits is the large address space to handle huge data sets. Trust me, in the "commercial" world, very few Alphas or SUN/Sparcs will ever have even close to 2**32 bytes of memory. The reall advantage has always been in floating point, especially double precision floating point performance.
www.SPEC.org has been benchmarking processors for many years, and several of their key benchmarks stress the double precision capability of the processor.
So do any members of the Athalon 64 family have "true" 64 bit internal data paths and registers ?
Another tip from the Alpha engineers. External data buses were as wide a 256 bits ! Helps to fill that cache fast !!
balzi - Wednesday, August 18, 2004 - link
And further more - the article states that there's 41 replies before this.. when only 14 show up -- this will be 15.."things are looking very fishy in Denmark"
"ahh Switzerland?"
"yes.. there too"
balzi - Wednesday, August 18, 2004 - link
I have to agree with johnsonx here.the graphs were extremely weird..
The order of the entries was rarely related to anything at all - like normally, the winner would be first, followed by second, etc.. or maybe you'd keep the same order for many different graphs from one benchmark.
The most annoying thing I came across was when a test was compiled with a bunch of flags.. the "Option" legend entries were exactly upside-down to the graphs.. my brain hurt trying to figure out what was benefitting where??.. owww!!!
just some thorts.. hope they help.
Balzi
frinky525 - Wednesday, August 18, 2004 - link
keep up the linux articles kris!jason tower
trilug treasurer
raleigh, nc
KristopherKubicki - Wednesday, August 18, 2004 - link
JohnsonX, i would agree with you except the fact that the Sempron 3100+ is really just a Newcastle with half cache disabled (and 64-bit disabled). The big difference is the on CPU memory controller.Kristopher
johnsonx - Wednesday, August 18, 2004 - link
Regarding model numbers, whatever AMD says the model number targets, what's important to remember is that the model number is only meant to be compared within a single AMD processor family. In the current scheme, Sempron model numbers mean less performance than AthlonXP model numbers, which in turn mean less performance than Athlon64 model numbers.This mostly works well except when AMD mixes two processors from different architectures into the same family as they have with the Sempron; it's really tough to apply the same metric to a K7 and a K8.
I'm not sure if AT has done this, but it might be interesting to compare an AXP 3200+ to a Sempron 3100+; in theory the extra 400Mhz of core clock and extra 256k of cache should enable the AXP to outrun the Sempron in most cases.
TrogdorJW - Wednesday, August 18, 2004 - link
Well, one thing that the benchmarks do show is how the Sempron 3100+ compares with the XP2200+ when they both have the same amount of cache and clock speed. The bus speed is something of a factor, but I doubt that would make up the remaining deficit in performance. It's pretty clear that the integrated memory controller on the Sempron is more than enough to help is pass the Athlon XP in typical Linux use.It would be interesting to see an XP-M Barton core clocked at 1.8 GHz with a 9X multiplier, just to take the bus speed out of the equation. But really, it's academic: for the price, the Sempron 3100+ is a good buy.
Regarding the conclusion with the comment on model numbers, I think it's fair enough for AMD to rate the Sempron agains the Celeron. Which is to say, I hate model numbers in general, but you already know that. :)