The NVIDIA Titan V Deep Learning Deep Dive: It's All About The Tensor Cores
by Nate Oh on July 3, 2018 10:15 AM ESTDAWNBench: Image Classification (CIFAR10)
In terms of real-world applicable performance, deep learning training is better described with time-to-accuracy and cost metrics. For DAWNBench, those measurements were the stipulations for each of the three subtests. For image classification with CIFAR10, these were:
- Training Time: Train an image classification model for the CIFAR10 dataset. Report the time needed to train a model with test set accuracy of at least 94%
- Cost: On public cloud infrastructure, compute the total time needed to reach a test set accuracy of 94% or greater, as outlined above. Multiply the time taken (in hours) by the cost of the instance per hour, to obtain the total cost of training the model
Here, we take two of the top-5 fastest CIFAR10 training implementations, both in PyTorch, and run them with our devices. The first, based on ResNet34, was created to run on a NVIDIA GeForce GTX 1080 Ti, while the second, based on ResNet18, was created to run on a single Tesla V100 (AWS p3.2large). Because these are recent top entries to DAWNBench, we can consider them to be reasonably modern, while understanding that CIFAR10 is not a hugely intensive dataset.
For our purposes, the tiny image dataset of CIFAR10 works fine as running a single-node on a dataset like ImageNet with non-professional hardware that could be old as Kepler, may result in unacceptably long training times for unlikely convergence. This is a useful result on its own but only after we have a fully detailed machine learning GPU benchmark suite.
The first implementation was designed to run on a single GTX 1080 Ti train, and the original submission noted that it took 35:37, or 35.6 minutes, to train to 94%.
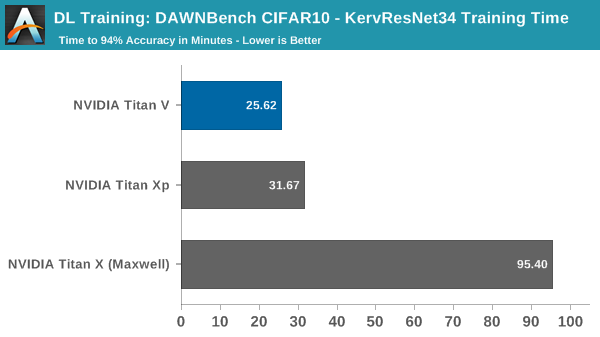
Even though we are training this on-premise, the cost metric is useful to compare against other graphics cards, though in this case we are talking about electricity differences of a few cents.
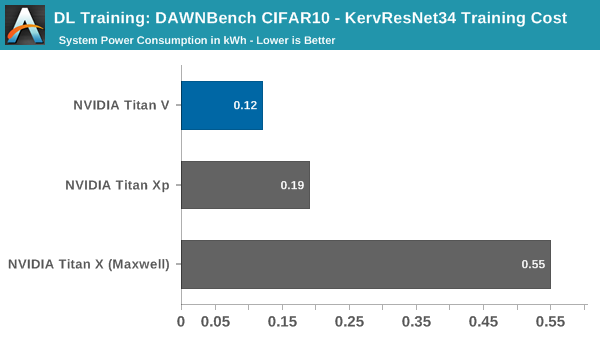
Using the Titan V in this circumstance does not take advantage of tensor cores, only its general improvements over Pascal. In this unoptimized setting, it runs in around 20% faster than the Titan Xp. Even still, the peak system consumption has dropped down by around 80W, though how much of that is due to the graphics card is unclear because of how the model deals with CPU usage and data pre-processing.
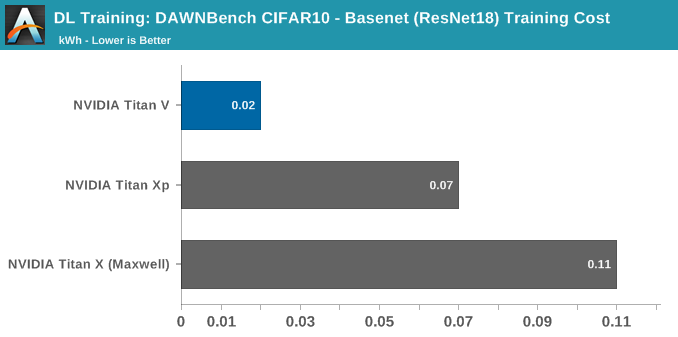
For the second implementation, the original submission reported the V100 training to 94% in 5:41, or 5.7 minutes.
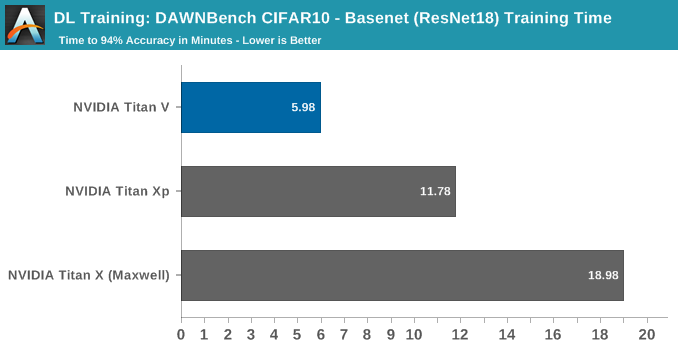
Without delving into and accurately analyzing the model code, it's not clear whether it takes advantage of tensor cores or not, since the model is plenty fast on Maxwell, let alone Volta.








65 Comments
View All Comments
SirCanealot - Tuesday, July 3, 2018 - link
No overclocking benchmarks. WAT. ¬_¬ (/s)Thanks for the awesome, interesting write up as usual!
Chaitanya - Tuesday, July 3, 2018 - link
This is more of an enterprise product for consumers so even if overclocking it enabled its something that targeted demographic is not going to use.Samus - Tuesday, July 3, 2018 - link
woooooooshMrSpadge - Tuesday, July 3, 2018 - link
He even put the "end sarcasm" tag (/s) to point out this was a joke.Ticotoo - Tuesday, July 3, 2018 - link
Where oh where are the MacOS drivers? It took 6 months to get the pascal Titan drivers.Hopefully soon
cwolf78 - Tuesday, July 3, 2018 - link
Nobody cares? I wouldn't be surprised if support gets dropped at some point. MacOS isn't exactly going anywhere.eek2121 - Tuesday, July 3, 2018 - link
Quite a few developers and professionals use Macs. Also college students. By manufacturer market share Apple probably has the biggest share, if not then definitely in the top 5.mode_13h - Tuesday, July 3, 2018 - link
I doubt it. Linux rules the cloud, and that's where all the real horsepower is at. Lately, anyone serious about deep learning is using Nvidia on Linux. It's only 2nd-teir players, like AMD and Intel, who really stand anything to gain by supporting niche platforms like Macs and maybe even Windows/Azure.Once upon a time, Apple actually made a rackmount OS X server. I think that line has long since died off.
Freakie - Wednesday, July 4, 2018 - link
Lol, those developers and professionals use their Macs to remote in to their compute servers, not to do any of the number crunching with.The idea of using a personal computer for anything except writing and debugging code is next to unheard of in an environment that requires the kind of power that these GPUs are meant to output. The machine they use for the actual computations are 99.5% of the time, a dedicated server used for nothing but to complete heavy compute tasks, usually with no graphical interface, just straight command-line.
philehidiot - Wednesday, July 4, 2018 - link
If it's just a command line why bother with a GPU like this? Surely integrated graphics would do?(Even though this is a joke, I'm not sure I can bear the humiliation of pressing "submit")